What is n8n?
Two of the most attractive use caes 1. Real-time Data Queries via Chat Use Case: A business owner messages the bot on Line or Telegram:“What’s today’s sales?” What Happens:The bot …
Technical sharing by programmers

Two of the most attractive use caes 1. Real-time Data Queries via Chat Use Case: A business owner messages the bot on Line or Telegram:“What’s today’s sales?” What Happens:The bot …
Usage scenario description: In 2014, when the company was founded, we took on an order management system for enterprise content. At that time, we used the latest technologies: Ubuntu 16.04, …

I have a Docker container that can run on a single machine, and I want to deploy it to the cloud. Please note that when you use a database, the …
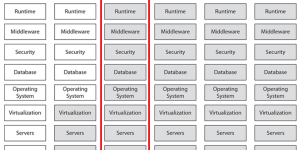
How to use Google Cloud Run to deploy your Docker Container.


There are five types of bottle cap defects Create Shape Model, Golden Image, and Mask Image Optical inspection process flow Create Shape Model Save Golden Images Save Mask Image Dirty …
video 17 母音: 3個雙母音 + 14個母音 24 子音: 15有聲子音,9無聲子音(氣音) 8組發音方法相同,一個有聲,一個無聲 四個有2種發音,母音前、母音後發不同音 另外3個有聲子音,1個無聲子音 拚音練習

Build Docker Environment I want to build a docker python development environment under Windows 11. Start Developing the logprob value more close to 0 is more confident. Argument: Stream Stream …

It be used for describing and matching patterns in the strings of text. 📌 Basic Syntax 🎯 Character Classes 🔢 Quantifiers 🎯 Groups & Capturing 🚀 Assertions & Anchors 🎏 …
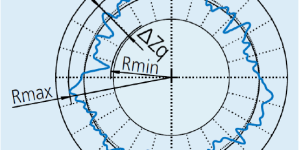
The O-ring is a circular gasket used for sealing applications. It is typically made of rubber, silicone, or other elastomeric materials. O-rings are designed to sit in a groove and …