稀疏矩陣(SparseMatrices)
稀疏矩陣相對於密集矩陣在處理大多數元素為零的大型數組時的效率。稀疏矩陣僅存儲非零元素及其位置,導致在某些操作中記憶體使用量和計算時間大幅減少。
Technical sharing by programmers
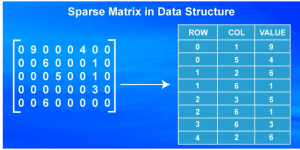
稀疏矩陣相對於密集矩陣在處理大多數元素為零的大型數組時的效率。稀疏矩陣僅存儲非零元素及其位置,導致在某些操作中記憶體使用量和計算時間大幅減少。
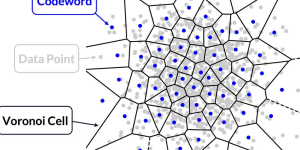
向量量化是一個通用術語,可以與信號處理、數據壓縮和聚類相關聯。在這裡,我們將專注於聚類組件,從如何將數據提供給vq包以識別聚類開始。
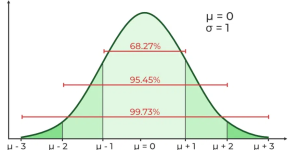
在SciPy的stats模塊中,norm代表正態分佈,也被稱為高斯分佈。正態分佈是一種連續概率分佈,其在平均值周圍對稱。 SciPy中的norm對象表示具有指定均值(loc)和標準差(scale)的正態分佈。它提供了各種方法來處理正態分佈,例如計算概率密度函數(PDF)、累積分佈函數(CDF)、生成隨機樣本等。 在提供的代碼中,norm用於創建一個具有均值(loc)為0和標準差(scale)為1的正態分佈對象。然後,使用這個分佈對象(dist)計算PDF、CDF,並從正態分佈生成隨機樣本。 在這個例子中,pdf 和 cdf 是根據模型預測的值,而 sample 是隨機模擬出的值,用於檢驗模型與實際數據的符合程度。 PDF 與 sample的分佈是一致。CDF(累積分佈函數)代表的是在某個數值之前的累積概率。對於正態分佈來說,當 x 值由-5往0時越接近平均值,累積概率越接近 0.5,這是因為正態分佈是對稱的, CDF在 x > 0 的區間,CDF 的值持續上升,而是趨於 1。這種情況下,如果模型的預測與實際數據相符,並且實際數據的分佈也表現出在這個區間的數值較大的趨勢,那麼可以認為模型是比較正確的
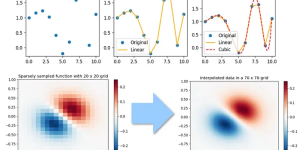
內插法是一種數學方法,用於在已知數據點之間估算未知點的值。在內插中,我們假設數據點之間的關係是連續且光滑的,並使用這種關係來預測未知位置的數值。 具體來說,當我們有一組離散的數據點,但我們想要在這些點之間的某個位置獲得更多的數據時,我們就可以使用內插法。它通常用於曲線擬合和數據補充的情況下,幫助我們理解數據的行為、預測趨勢或填補缺失的數據。 在內插中,我們根據已知的數據點來建立一個函數或曲線,該函數或曲線在這些點上通過已知的數據點,並且在這些點之間是連續且光滑的。然後,我們使用這個函數或曲線來估算我們感興趣的位置的值。 內插法有很多種類,包括線性內插、多項式內插、樣條內插等。選擇適當的內插方法取決於數據的特性和應用的需求 SciPy提供了十幾種不同的插值函數,從簡單的單變量情況到複雜的多變量情況。當樣本數據可能由一個獨立變量引導時,使用單變量插值,而多變量插值則假設存在多個獨立變量。 內插法有兩種基本方法:(1)對整個數據集擬合一個函數或(2)用多個函數擬合數據集的不同部分,其中每個函數的連接部分平滑地連接在一起。 我們接下來使用一個複雜的邏輯來產生數據,再使用Scipy的內插(擬合)函式來找出合適的資料模型函式。