Efficient Multi-Model Inference with 4-bit Quantization in Hugging Face Transformers
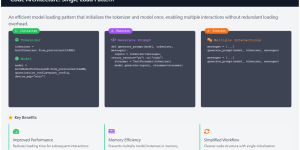
Introduction In this large language model Colab tutorial, I’ll walk you through how to efficiently load and run multiple large language models (LLMs) in Hugging Face Transformers using 4-bit quantization …