Proposition Logic
Propositional logic (also called proposition logic, sentential logic, or Boolean logic) is a branch of logic that deals with propositions and their truth values—true or false.
Technical sharing by programmers

Propositional logic (also called proposition logic, sentential logic, or Boolean logic) is a branch of logic that deals with propositions and their truth values—true or false.

Build Docker Environment I want to build a docker python development environment under Windows 11. Start Developing the logprob value more close to 0 is more confident. Argument: Stream Stream …

噴液異常視覺檢測 鴻博資訊有限公司 系統架構圖 此專案規劃一台電腦最多可以跑四隻AOI程式,同時跑多隻AOI程式時的運行順暢度取決於電腦硬體本身的規格。 AOI程式與Modbus程式間是透過Socket進行通訊,每隻AOI程式需配置一個唯一序號,1到4號,當AOI程式偵測到異常時會發送一個訊號給Modbus程式,Modbus根據訊號中的AOI程式唯一序號,在對應的PLC Modbus位址上發送一個100 ms的ON訊號。 AOI ID Modbus Address 1 100 2 101 3 102 4 103 工業相機 官網:https://www.toshiba-teli.co.jp/en/products/industrial-camera/index.htm 請點選【Support】【Software Download】下載軟體SDK 【註】使用Ubuntu 22.04 下載TeliCamSDKforLinux_S5104031.zip 壓縮檔內容 請開啟Readme檔案 程式安裝路徑 /opt/TeliCamSDK …

Seaborn資料分析 + Sklearn Seaborn 資料集中的 “tips” 是一個包含餐廳小費資料的資料集。這個資料集通常用於示範 Seaborn 中的數據可視化功能和統計分析。 “tips” 資料集包含了餐廳服務員收到的小費金額以及與小費相關的一些額外信息,例如顧客人數、就餐日期和時間、就餐者的性別、是否是吸煙區域、就餐的星期幾等等。這些信息可以用於探索性數據分析、統計分析以及建模工作。 這個資料集的結構通常包含以下幾個欄位: 這個資料集是 Seaborn 中內建的範例資料集之一,通常用於示範 Seaborn 中各種圖表的繪製和數據分析。 Seaborn 資料集中的 “diamonds” 是一個包含鑽石價格和屬性的資料集。這個資料集通常用於示範 Seaborn 中的數據可視化功能和統計分析。 “diamonds” 資料集包含了各種鑽石的屬性和價格信息。這些屬性包括鑽石的重量(克拉)、切工、顏色、淨度等,而價格則是以美元為單位。 這個資料集的結構通常包含以下幾個欄位: 這個資料集通常用於示範 Seaborn 中的散點圖、直方圖、盒圖等圖表的繪製,以及數據探索和統計分析。 Categorical …
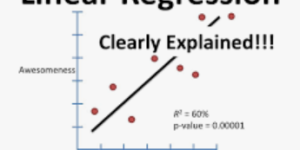
首先,使用make_regression函數生成了一些合成數據,然後將數據分成訓練集和測試集。接著創建了LinearRegression模型的實例,並使用訓練集對模型進行訓練。訓練完成後,打印出了模型的係數和對新數據的預測結果。最後,通過可視化將訓練集和測試集的散點圖以及線性回歸的平面呈現出來。

DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一種密度聚類算法,用於將數據點劃分為多個集群,同時可以識別和排除噪音點。該算法基於以下概念: DBSCAN算法運行步驟如下: DBSCAN的主要優勢是: 總的來說,DBSCAN是一種強大的聚類算法,特別適用於處理具有不同密度和形狀的數據集。
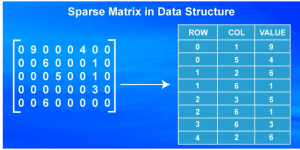
稀疏矩陣相對於密集矩陣在處理大多數元素為零的大型數組時的效率。稀疏矩陣僅存儲非零元素及其位置,導致在某些操作中記憶體使用量和計算時間大幅減少。
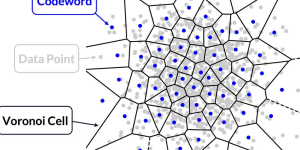
向量量化是一個通用術語,可以與信號處理、數據壓縮和聚類相關聯。在這裡,我們將專注於聚類組件,從如何將數據提供給vq包以識別聚類開始。
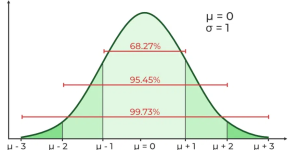
在SciPy的stats模塊中,norm代表正態分佈,也被稱為高斯分佈。正態分佈是一種連續概率分佈,其在平均值周圍對稱。 SciPy中的norm對象表示具有指定均值(loc)和標準差(scale)的正態分佈。它提供了各種方法來處理正態分佈,例如計算概率密度函數(PDF)、累積分佈函數(CDF)、生成隨機樣本等。 在提供的代碼中,norm用於創建一個具有均值(loc)為0和標準差(scale)為1的正態分佈對象。然後,使用這個分佈對象(dist)計算PDF、CDF,並從正態分佈生成隨機樣本。 在這個例子中,pdf 和 cdf 是根據模型預測的值,而 sample 是隨機模擬出的值,用於檢驗模型與實際數據的符合程度。 PDF 與 sample的分佈是一致。CDF(累積分佈函數)代表的是在某個數值之前的累積概率。對於正態分佈來說,當 x 值由-5往0時越接近平均值,累積概率越接近 0.5,這是因為正態分佈是對稱的, CDF在 x > 0 的區間,CDF 的值持續上升,而是趨於 1。這種情況下,如果模型的預測與實際數據相符,並且實際數據的分佈也表現出在這個區間的數值較大的趨勢,那麼可以認為模型是比較正確的
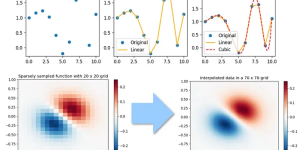
內插法是一種數學方法,用於在已知數據點之間估算未知點的值。在內插中,我們假設數據點之間的關係是連續且光滑的,並使用這種關係來預測未知位置的數值。 具體來說,當我們有一組離散的數據點,但我們想要在這些點之間的某個位置獲得更多的數據時,我們就可以使用內插法。它通常用於曲線擬合和數據補充的情況下,幫助我們理解數據的行為、預測趨勢或填補缺失的數據。 在內插中,我們根據已知的數據點來建立一個函數或曲線,該函數或曲線在這些點上通過已知的數據點,並且在這些點之間是連續且光滑的。然後,我們使用這個函數或曲線來估算我們感興趣的位置的值。 內插法有很多種類,包括線性內插、多項式內插、樣條內插等。選擇適當的內插方法取決於數據的特性和應用的需求 SciPy提供了十幾種不同的插值函數,從簡單的單變量情況到複雜的多變量情況。當樣本數據可能由一個獨立變量引導時,使用單變量插值,而多變量插值則假設存在多個獨立變量。 內插法有兩種基本方法:(1)對整個數據集擬合一個函數或(2)用多個函數擬合數據集的不同部分,其中每個函數的連接部分平滑地連接在一起。 我們接下來使用一個複雜的邏輯來產生數據,再使用Scipy的內插(擬合)函式來找出合適的資料模型函式。