模擬不同高度量測物件尺寸
光學校正: 光學校正的步驟 尺寸量測的步驟 關鍵元件: NO 規格 相片 1 UI-3884LEResolution:6.41 MPixOptical class:1/1.8″Pixel size:2.40 µm 2 6mm FL, Liquid Lens M12 LensFocal Length FL (mm): 6.0mm 3 校正片7×7 12.5mm 4 筆記本21 cm …
Technical sharing by programmers
光學校正: 光學校正的步驟 尺寸量測的步驟 關鍵元件: NO 規格 相片 1 UI-3884LEResolution:6.41 MPixOptical class:1/1.8″Pixel size:2.40 µm 2 6mm FL, Liquid Lens M12 LensFocal Length FL (mm): 6.0mm 3 校正片7×7 12.5mm 4 筆記本21 cm …

篩網砂石視覺檢測系統 鴻博資訊有限公司 公司簡介: 我們是一家於2015年成立的公司,專注於客製化視覺系統的開發。在成立前也從事視覺檢測相關領域的研究開發,憑藉著十幾年的豐富經驗,我們致力於提供高品質的視覺檢測解決方案。 我們的優勢: 我們的服務範圍包括3D資料處理、高光譜資料分析、熱影像檢測等。無論您的應用場景是什麼,我們都能夠提供專業的視覺檢測解決方案,以滿足您的需求。 我們引以為傲的是與日商睿怡科技股份公司的深度合作。通過與睿怡科技股份公司的合作,我們得以獲取最新的自動化技術和解決方案,並將其應用於我們的視覺系統開發中,以提供客戶更高效、更精準的解決方案。 我們的目標是繼續專注於創新和技術發展,為客戶提供最優質的產品和服務。如需進一步了解我們的產品和服務,請訪問我們的官方網站或通過以下方式聯繫我們 謝謝您對我們公司的關注,我們期待與您合作! 視覺檢測系統硬體架構 NO 項目 備註 1 TOSHIBA Teli USB3 Camera BU040MCG 日本製 2 Raspberry PI 5 Model B 8G 英國製 3 Myutron …
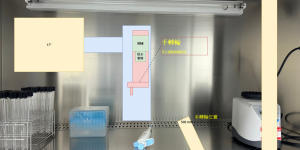
滅菌倉植物分株專案規劃 硬體規劃 前視 上視 側視 實際影像示意 主要硬體 電腦放置位置 軟體規劃 使用案例 類別圖 使用者操作界面
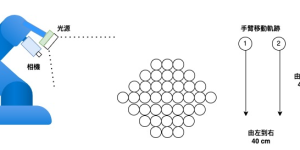
進料 出料 機台允許的檢測空間,只能從機台的下方空間找位置進行相機的架設。 架設要求,相機與紙張Z軸需要盡量平行,不要有傾斜角度(這個會大副度影像精度) 實驗 (Z軸與相機需平行,傾斜情況越大誤差越大) 左側 右側 左側情況先進行光學校正。 左側實際量測出來為199.2136 mm 誤差0.7864mm 右側實際量測出來為198.7449 mm 誤差1.2551mm

鏡架螺絲有無檢測 影像檢測手法的基礎觀念 影像直方圖 直方圖表示影像中像素強度(無論是彩色或灰階)的分佈。它可以視覺化為圖表(或繪圖),可以直觀地了解強度(像素值)分佈。在此範例中,我們將假設 RGB 色彩空間,因此這些像素值將在 0 到 255 的範圍內。 繪製直方圖時,x 軸充當我們的「箱」。如果我們用 256 建構一個直方圖 bin,那麼我們就可以有效地計算每個像素值出現的次數。 相反,如果我們只使用 2 (等距)容器,然後我們計算像素在 [0, 128] 或 [128, 255] 範圍內的次數。 然後將與 x 軸值合併的像素數繪製在 y 軸上。 讓我們看一個範例圖像以使這一點更清楚: …
鐵條計數 傳統影像處理 較佳的影像呈現效果 較差的影像呈現效果 使用面掃描的相機取像的問題 必需使用線掃描的影像處理才能得到最佳影像 理想的影像 分析後得到數量39 電腦視覺軟硬體架構 NO 品項 預估金額 1 工業電腦 2 線掃描相機 3 線掃描相機鏡頭 4 線掃描光源 5 線掃描光源控制器 6 AOI軟體

紙張尺寸量測 方案一 A4 紙張 寬x高 210mm x 297mm 使用「校正塊」,校正塊的直徑為31mm 使用工業相機拍攝校正塊 使用AOI程式檢測校正塊 校正塊寬度為248像素 計算「像素 VS 實際尺寸」轉換比例 31 mm / 248 = 0.125 mm 使用工業相機拍A4紙張 使用AOI程式量測A4紙張 A4紙張量測寬度為1680.06像素 AOI量測像素 X 轉換比例 = 實際尺寸 …

Seaborn資料分析 + Sklearn Seaborn 資料集中的 “tips” 是一個包含餐廳小費資料的資料集。這個資料集通常用於示範 Seaborn 中的數據可視化功能和統計分析。 “tips” 資料集包含了餐廳服務員收到的小費金額以及與小費相關的一些額外信息,例如顧客人數、就餐日期和時間、就餐者的性別、是否是吸煙區域、就餐的星期幾等等。這些信息可以用於探索性數據分析、統計分析以及建模工作。 這個資料集的結構通常包含以下幾個欄位: 這個資料集是 Seaborn 中內建的範例資料集之一,通常用於示範 Seaborn 中各種圖表的繪製和數據分析。 Seaborn 資料集中的 “diamonds” 是一個包含鑽石價格和屬性的資料集。這個資料集通常用於示範 Seaborn 中的數據可視化功能和統計分析。 “diamonds” 資料集包含了各種鑽石的屬性和價格信息。這些屬性包括鑽石的重量(克拉)、切工、顏色、淨度等,而價格則是以美元為單位。 這個資料集的結構通常包含以下幾個欄位: 這個資料集通常用於示範 Seaborn 中的散點圖、直方圖、盒圖等圖表的繪製,以及數據探索和統計分析。 Categorical …

客戶需求:使用者會將PDF中的標籤內容印刷到白色的織布上,希望透過視覺檢測可以將印刷不良的情況偵測出來。 我們將計劃使用局部可變形模型來進行標籤內容在織布上的視覺檢測,提供更精細的測試。 局部可變形模型是一種用於視覺檢測的技術,它可以在圖像中尋找局部特定形狀的實例。這種模型具有一定的靈活性,可以應對目標物體在圖像中的變形、旋轉和縮放等情況。 以下是局部可變形模型的一些重要特點和工作原理: 實驗一 我們故意將這張影像上幾處位置,故以把黑色的區域塗白。看看是否可以將差異處檢測出來? 可以看到左像影像比對出來異常的位置。這幾處位置是塗白的位置。 實驗二 可以看到QRCode被圖白的區域也有偵測出來。 AOI程式比對結果 比對原始資料一 比對原始資料二 比對原始資料三

客戶需求∶ 我需要檢測車燈的打出來的光的顏色組成,如果超出範圍則發出警示。 檢測手法∶ 色相直方圖分佈∶ 影像的色相直方圖分佈是描述影像中不同色相值的統計分佈情況。在色相直方圖中,色相值通常被劃分成若干個區間,例如0到180度之間的若干個小區間。然後,統計圖像中每個區間內像素的數量或者像素的比例,形成一個直方圖。 色相直方圖可以反映出圖像中各個色相的分布情況,即哪些色相在圖像中佔據主導地位,哪些色相較少出現。通過觀察色相直方圖,可以直觀地了解圖像的整體顏色分布情況,以及圖像中具體顏色的特徵。 通常,色相直方圖是基於圖像的色彩空間進行計算的,例如RGB色彩空間或者HSV色彩空間。在HSV色彩空間中,色相(Hue)表示顏色的種類或者色調,因此色相直方圖反映了圖像中不同種類顏色的分布情況。 通過比較不同圖像的色相直方圖分佈,我們可以評估它們之間的顏色相似度或者差異度,從而用於圖像檢索、圖像分類、圖像匹配等領域。 歸一相似度∶ “歸一相似度”(Normalized Similarity)指的是將相似度值歸一化到特定的範圍內,通常是0到1之間。這樣做的目的是使得相似度值更易於理解和比較,不受圖像尺寸、亮度等因素的影響。 在計算兩個直方圖的相似度時,我們可以得到一個原始的相似度值,表示它們之間的相似程度。但是這個值的範圍通常不是固定的,並且可能受到直方圖的大小、圖像的亮度等因素的影響。因此,將這個相似度值歸一化到0到1之間可以消除這些影響,使得相似度更具有可比性。 在歸一化相似度中,常見的做法是使用以下公式: 歸一化相似度=原始相似度直方圖1的總和+直方圖2的總和−原始相似度 歸一化相似度= 直方圖1的總和+直方圖2的總和−原始相似度 原始相似度 這樣得到的歸一化相似度值會保證在0到1之間,其中1表示完全相同,0表示完全不同。 合格 相似度:0.987 偏紅 相似度:0.552 偏黃 相似度:0.231 偏綠 相似度:0.318 偏藍 相似度:0.239