GPT and Claude In Gradio UI
Gradio is an open-source Python framework that makes it easy to build interactive web-based UIs for machine learning (ML) models, data pipelines, or any Python function. Instead of writing frontend …
Technical sharing by programmers
Gradio is an open-source Python framework that makes it easy to build interactive web-based UIs for machine learning (ML) models, data pipelines, or any Python function. Instead of writing frontend …

You’re already familar with prompts being organized into lists like: In fact this structure can be used to reflect a longer conversation history: Import Rule: Please remember this prompt rule. …

One-Shot The Website class retrieves the text content and links from a given URL. Prompt 1: Here’s an OpenAI example showing how to use a one-shot prompt to get a …
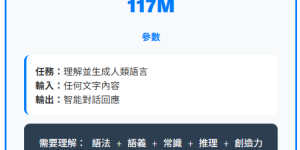
🔍 問題的複雜度差異 Linear Regression (線性回歸) ChatGPT (語言模型) 🧠 參數用途大解析 1. 詞彙表示 (Vocabulary Embeddings) 光是把每個詞轉換成電腦能理解的數字就需要2560萬個參數! 2. 多頭注意力機制 (Multi-Head Attention) 3. 多層堆疊 🤔 為什麼需要這麼多參數? 複雜度對比 任務輸入複雜度輸出複雜度所需知識線性回歸數值特徵單一數值數學關係ChatGPT自然語言創意文本人類所有知識 語言的複雜性 1. 語義理解 2. 上下文依賴 3. …

React: The library for web and native user interfaces Destructing Objects and Arrays Rest/Spread Operator Spread Operator (…) Expands (spreads) an array or object into individual elements. Rest Operator (…) …

Exentsions Settings Code Snippets 1. “Print to console” 👉 Usage: type cl → Tab → console.log(<cursor>) 2. “reactComponent” 👉 Usage: type rfc → Tab → ready-to-use React function component 3. …
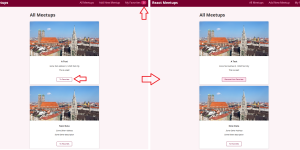
Context provides a way to pass data through the component tree without having to pass props down manually at every level. In a typical React application, data is passed top-down …

Propositional logic (also called proposition logic, sentential logic, or Boolean logic) is a branch of logic that deals with propositions and their truth values—true or false.
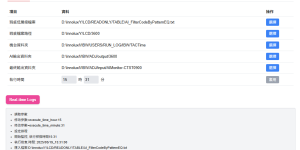
The customer’s computer environment is quite complex, with machines running Windows 7, Windows 10, and Windows 11. Although the PyQt application we developed works on about 90% of these systems, …
This is docker-compose.yml, execute the command: docker compose up -d to run the RStudio Container. Then open your browser to http://localhost:8787/, you can see the login dialog, please input rstudio/yourpassword …