鐵條計數
鴻博資訊有限公司
鐵條影像


採用AI的物件偵測邏輯
AI的物件偵測的邏輯是基於計算機視覺(Computer Vision)和深度學習技術。它的核心是透過模型學習如何從影像中自動識別出物件的位置和類別。以下是物件偵測的基本邏輯,以及它如何確定影像中的物件數量和位置。
1. 基礎概念:分類與定位
物件偵測結合了兩個主要的任務:
- 分類(Classification):識別影像中是否存在特定類別的物件,例如「貓」或「車」。
- 定位(Localization):確定物件在影像中的具體位置,通常用矩形邊界框來表示。
2. 物件偵測的主要流程
1. 特徵提取(Feature Extraction)
- 首先,深度學習模型(如卷積神經網路,CNN)會對輸入的影像進行特徵提取。這些特徵是影像中高維度的表示,能夠捕捉到物件的邊緣、顏色、形狀、紋理等信息。
- 模型通過多層卷積層逐步提取出影像的不同層級特徵,從低層次的邊緣和紋理到高層次的形狀和物件結構。
2. 區域提議(Region Proposals)或網格劃分
- 許多物件偵測算法會將影像分割成小區域,這些區域稱為“候選區域”或網格,並在每個區域中嘗試檢測物件。
- 兩種主要的技術:
- 區域提議(Region Proposal Networks, RPN):例如 Faster R-CNN 中,RPN 會提議潛在的物件區域並進行分類。
- 網格劃分(Grid Division):YOLO 將整張影像劃分為若干個小網格,每個網格負責檢測位於其內部的物件。
3. 邊界框回歸(Bounding Box Regression)
- 每個候選區域或網格會預測物件的邊界框(bounding box)。邊界框由四個數據組成:物件的左上角座標和右下角座標,或物件的中心點座標加上寬度和高度。
- 邊界框回歸是基於對目標物件位置的估計,模型學習如何根據特徵調整這些估計,使預測框與物件的實際位置更精確。
4. 分類與置信度預測
- 除了預測邊界框之外,模型還會對每個預測框中的物件進行分類。模型輸出物件的類別(例如「狗」、「貓」)以及對該預測的置信度分數。
- 如果置信度低於某個閾值,則會將這些框過濾掉,保留高置信度的預測。
5. 非極大值抑制(Non-Maximum Suppression, NMS)
- 當一個物件被多個框檢測到時,NMS 用來消除重疊度過高的邊界框。這一步是根據每個框的置信度來選擇,保留置信度最高的邊界框,並刪除其他重疊的框。
- 這樣做可以避免多個框重疊預測同一個物件。
3. AI如何確定影像中的物件數量及位置?
1. 確定物件數量
- 通過非極大值抑制(NMS),模型最終只保留每個物件的一個預測邊界框。剩下的框數量就是偵測到的物件數量。
- 如果沒有預測框被保留,則表示該影像中沒有偵測到任何物件。
2. 確定物件位置
- 每個物件的邊界框代表了物件在影像中的具體位置。邊界框的座標通常由左上角點的座標和右下角點的座標來表示。
- 對於每一個物件,模型預測出它在影像中的位置(邊界框座標)以及它的類別。
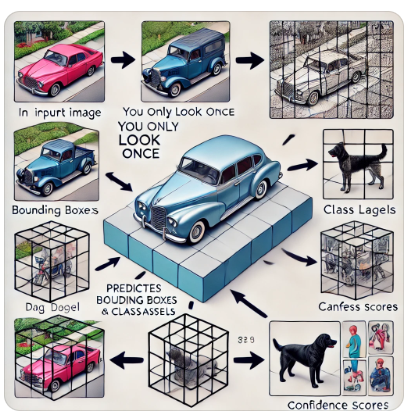
展示瞭如何將圖像劃分為網格,使用邊界框和標籤來檢測和分類汽車、狗和人等物件。
使用AI技術進行實驗
第一步:拍攝多張影像
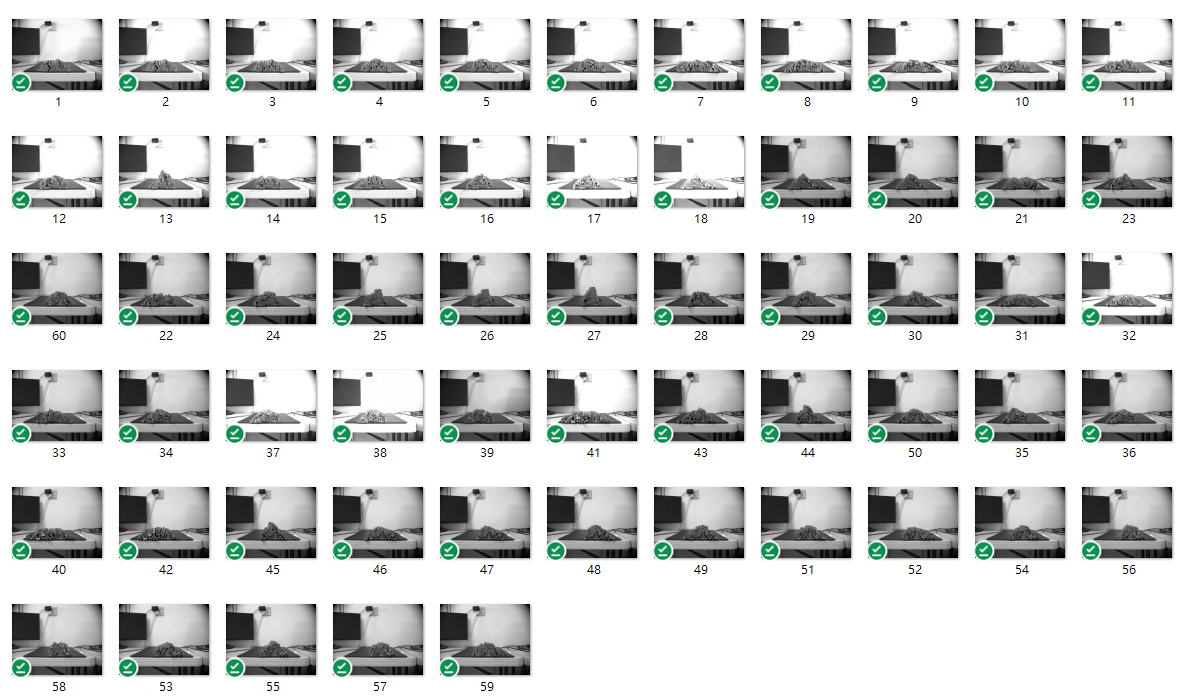
第二步:影像變形增量(變暗、變亮、放大、縮小、旋轉)

第三步:影像標記
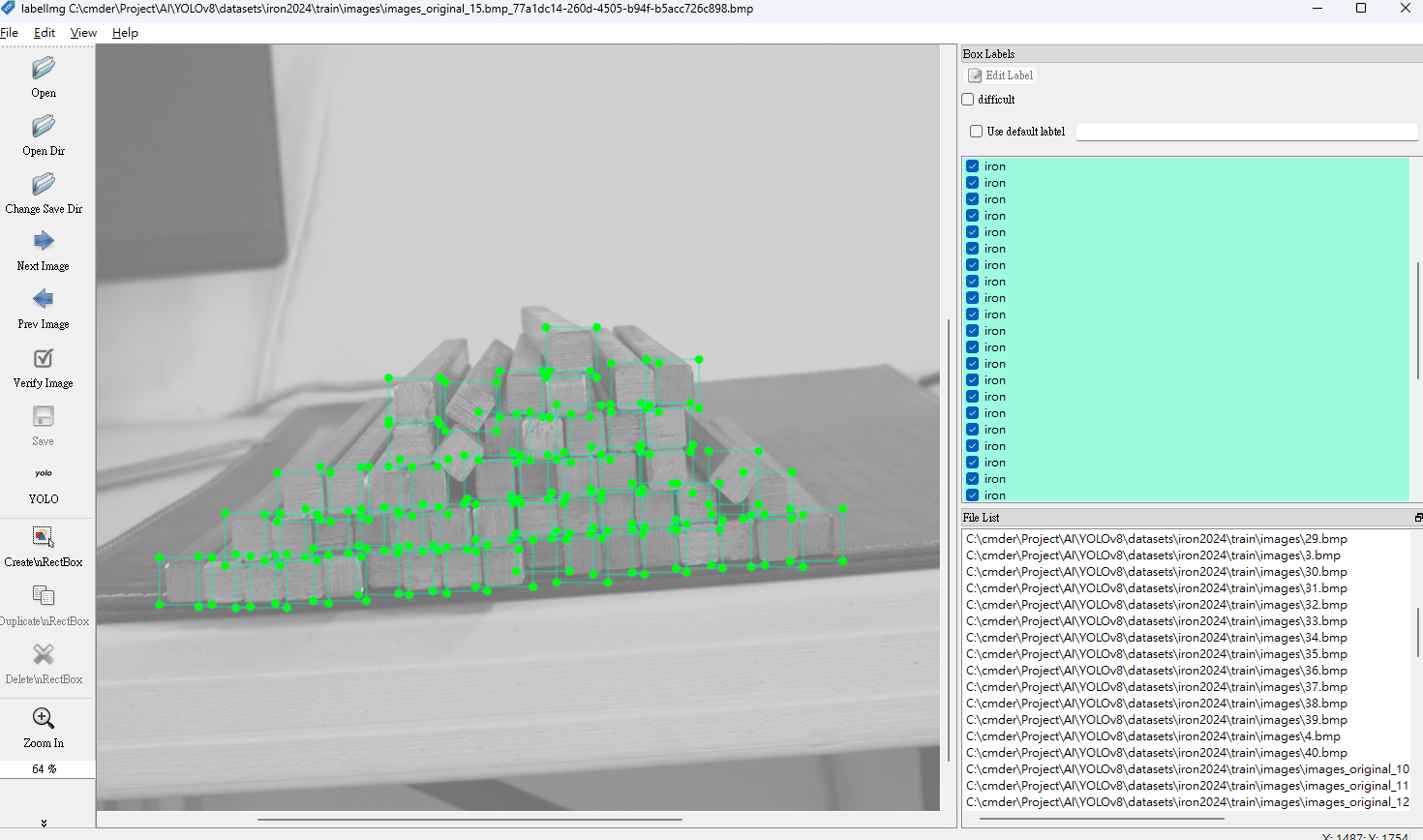
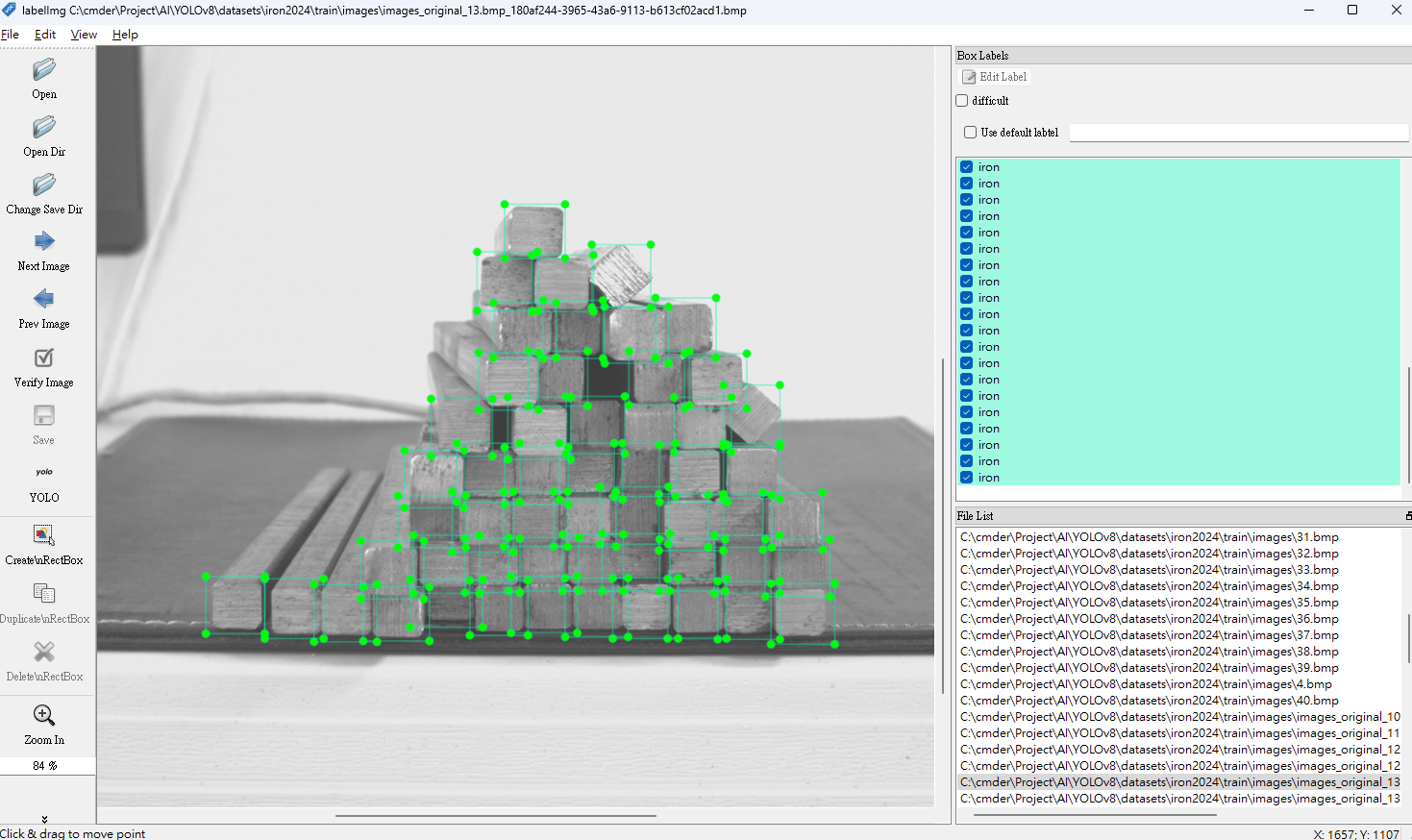
第三步:訓練AI模型
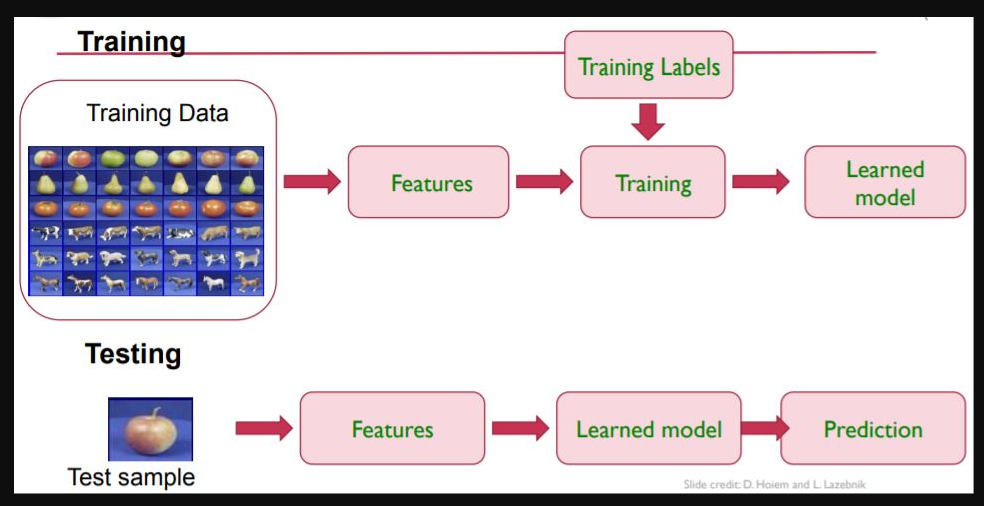
第四步:訓練AI模型驗証、測試
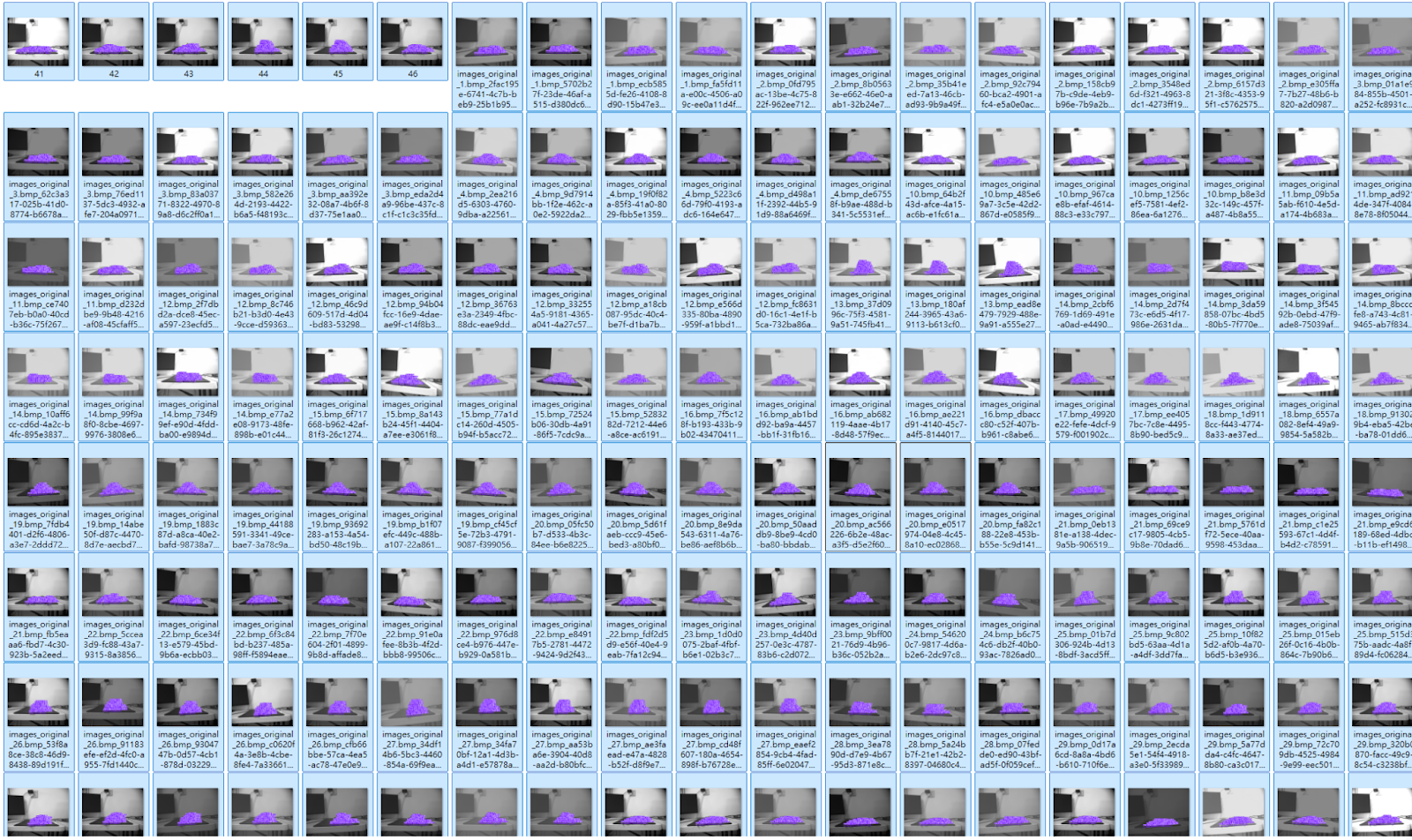
206張實驗
在極暗、極亮、傾斜影像下的實驗結果






取像環境的規劃
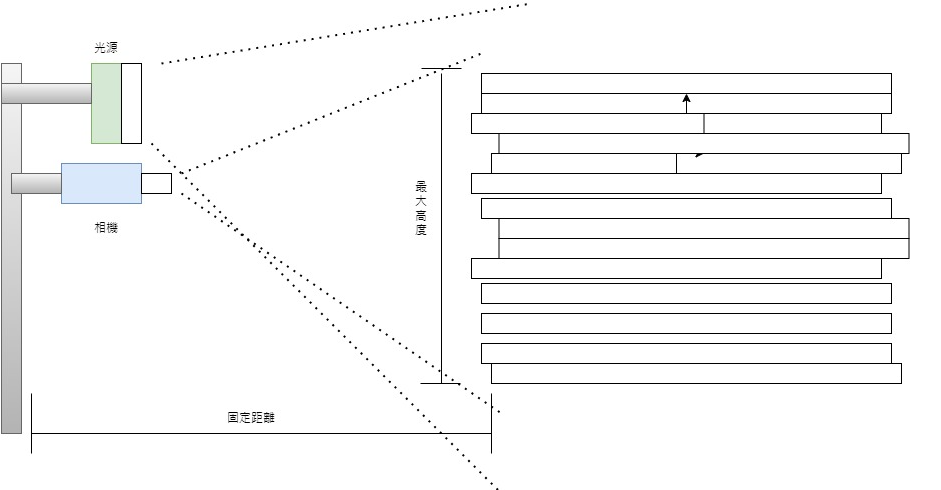
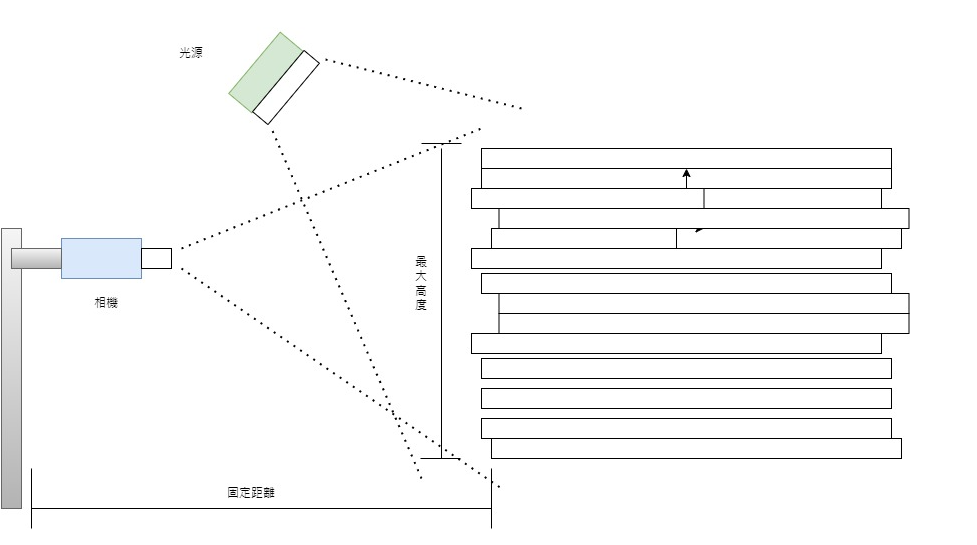
- 鐵鯈放置區域為乾淨較無干擾的背景
- 配置合適的相機及光源