🧭 Introduction: Why Modal?
Traditionally, deploying AI models in the cloud is a painful process:
- Set up GPU virtual machines
- Install Docker, CUDA, PyTorch
- Configure servers (Flask / FastAPI)
- Manage secrets, storage, and networking
Modal completely changes that.
It lets you define your infrastructure as code — in pure Python.
You just declare your environment (GPU, secrets, volumes), and Modal spins up a ready-to-run container on demand.
Modal is perfect for:
- Hosting Hugging Face models for inference
- Deploying fine-tuned LLMs
- Running batch jobs or pipelines
- Prototyping and experimentation
⚙️ Step 1: Environment Setup
After signing up for Modal, you’ll receive $30 of free credits for trial use.
In this example, you’ll also need a Hugging Face API token.
First, obtain your token from Hugging Face, then go to the Secrets page in Modal and create a new secret named hf-secret.
pip install modal
python3 -m modal setup
It will generate ~/.modal.toml
the content of .modal.toml
[fluber-course]
token_id = "ak-xxxxxxxxxxxxxxxxxxxxxxxx"
token_secret = "as-xxxxxxxxxxxxxxxxxxxxxxx"
active = true🧱 Step 2: Project Structure
Create a simple project folder:
pricer/
├── pricer_service2.py
└── requirements.txt (optional)💻 Step 3: Main Code
In this example, I use meta-llama/Meta-Llama-3.1-8B as the base model and load my fine-tuned version from Hugging Face.
Modal allows me to define the entire cloud environment using a simple decorator, @modal.cls, including:
- GPU type (e.g., T4)
- Container image
- Secret management (e.g., Hugging Face token)
- Volume caching (to avoid repeatedly downloading the model)
#pricer_service2.py
import modal
from modal import App, Volume, Image
# Setup - define our infrastructure with code!
app = modal.App("pricer-service")
image = Image.debian_slim().pip_install("huggingface", "torch", "transformers", "bitsandbytes", "accelerate", "peft")
# This collects the secret from Modal.
# Depending on your Modal configuration, you may need to replace "hf-secret" with "huggingface-secret"
secrets = [modal.Secret.from_name("hf-secret")]
# Constants
GPU = "T4"
BASE_MODEL = "meta-llama/Meta-Llama-3.1-8B"
PROJECT_NAME = "pricer"
HF_USER = "ed-donner" # your HF name here! Or use mine if you just want to reproduce my results.
RUN_NAME = "2024-09-13_13.04.39"
PROJECT_RUN_NAME = f"{PROJECT_NAME}-{RUN_NAME}"
REVISION = "e8d637df551603dc86cd7a1598a8f44af4d7ae36"
FINETUNED_MODEL = f"{HF_USER}/{PROJECT_RUN_NAME}"
CACHE_DIR = "/cache"
# Change this to 1 if you want Modal to be always running, otherwise it will go cold after 2 mins
MIN_CONTAINERS = 0
QUESTION = "How much does this cost to the nearest dollar?"
PREFIX = "Price is $"
hf_cache_volume = Volume.from_name("hf-hub-cache", create_if_missing=True)
@app.cls(
image=image.env({"HF_HUB_CACHE": CACHE_DIR}),
secrets=secrets,
gpu=GPU,
timeout=1800,
min_containers=MIN_CONTAINERS,
volumes={CACHE_DIR: hf_cache_volume}
)
class Pricer:
@modal.enter()
def setup(self):
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, set_seed
from peft import PeftModel
# Quant Config
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4"
)
# Load model and tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
self.tokenizer.pad_token = self.tokenizer.eos_token
self.tokenizer.padding_side = "right"
self.base_model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
quantization_config=quant_config,
device_map="auto"
)
self.fine_tuned_model = PeftModel.from_pretrained(self.base_model, FINETUNED_MODEL, revision=REVISION)
@modal.method()
def price(self, description: str) -> float:
import os
import re
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, set_seed
from peft import PeftModel
set_seed(42)
prompt = f"{QUESTION}\n\n{description}\n\n{PREFIX}"
inputs = self.tokenizer.encode(prompt, return_tensors="pt").to("cuda")
attention_mask = torch.ones(inputs.shape, device="cuda")
outputs = self.fine_tuned_model.generate(inputs, attention_mask=attention_mask, max_new_tokens=5, num_return_sequences=1)
result = self.tokenizer.decode(outputs[0])
contents = result.split("Price is $")[1]
contents = contents.replace(',','')
match = re.search(r"[-+]?\d*\.\d+|\d+", contents)
return float(match.group()) if match else 0🔑 Step 4: Configure Secrets and Volumes
Create a Hugging Face secret
modal secret create hf-secretEnter your Hugging Face token:
HF_TOKEN=<your_huggingface_token>Create a cache volume (optional)
modal volume create hf-hub-cache☁️ Step 5: Deploy and Run
import os
os.environ["MODAL_TOKEN_ID"] = "ak-xxxxxxxxxxxxxxxxxxxxxxxx"
os.environ["MODAL_TOKEN_SECRET"] = "as-xxxxxxxxxxxxxxxxxxxxxxx"
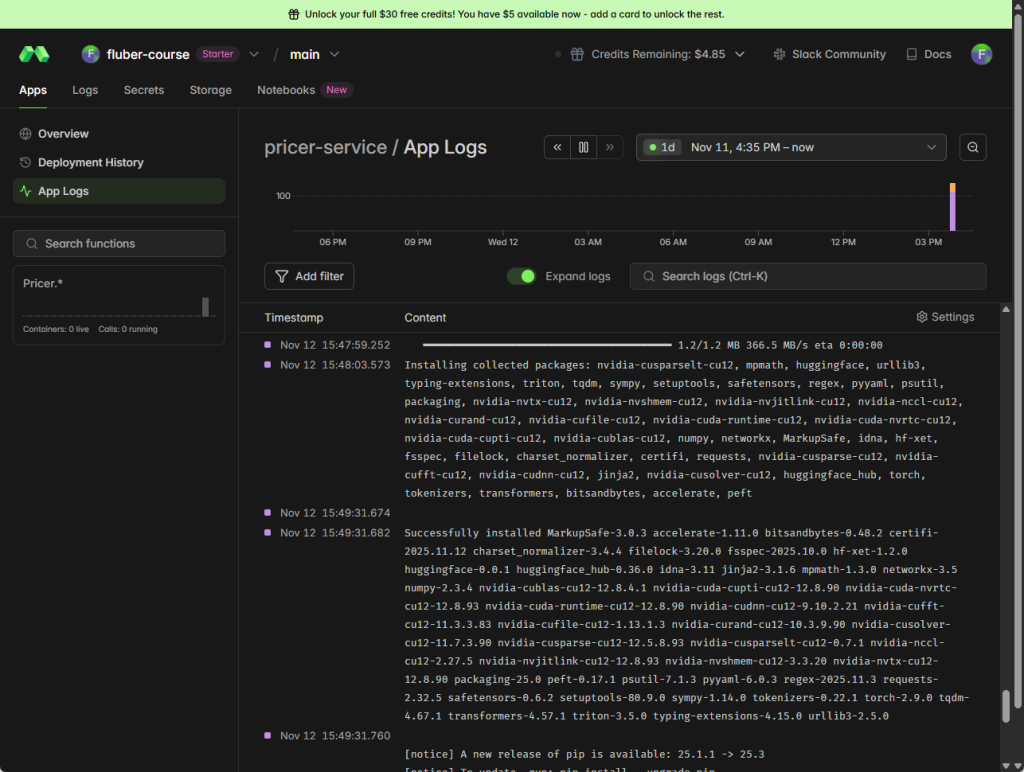
!modal deploy -m pricer_service2Modal automatically builds the container, starts the GPU, configures secrets, mounts volumes,
and provides a callable cloud endpoint (URL).
Pricer = modal.Cls.from_name("pricer-service", "Pricer")
pricer = Pricer()
reply = pricer.price.remote("Quadcast HyperX condenser mic, connects via usb-c to your computer for crystal clear audio")
print(reply)