Introduction
In this large language model Colab tutorial, I’ll walk you through how to efficiently load and run multiple large language models (LLMs) in Hugging Face Transformers using 4-bit quantization with BitsAndBytes. This Colab tutorial for large language models also covers how to manage multiple models in a single script, minimizing GPU memory usage and maximizing inference speed.
1. What is 4-bit Quantization?
Large language models like LLaMA, Phi-3, or Mixtral can easily occupy tens of gigabytes in GPU memory. Running multiple models simultaneously or even one model on a limited GPU can be challenging.
4-bit quantization is a technique that compresses model weights from 16/32-bit floating point to just 4 bits, drastically reducing memory usage.
In our script, we use BitsAndBytesConfig:
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant="nf4"
)load_in_4bit=True: Load the model weights as 4-bit.
bnb_4bit_compute_dtype=torch.float16: Compute in 16-bit for higher precision during inference.
bnb_4bit_use_double_quant=True: Use double quantization to reduce quantization error.
bnb_4bit_quant="nf4": Use Normal Float 4 (NF4) format, which preserves precision better than pure int4.
2. Loading Multiple Models Efficiently
Instead of reloading a model every time you want to generate text, we load each model once and store it in a dictionary:
loaded_models = {}
def load_model(model_name: str):
if model_name in loaded_models:
return loaded_models[model_name]
tokenizer = AutoTokenizer.from_pretrained(MODEL_DICT[model_name])
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
MODEL_DICT[model_name],
quantization_config=quant_config,
device_map="auto"
)
loaded_models[model_name] = (model, tokenizer)
return model, tokenizer- This approach avoids repeated model loading, saving both time and GPU memory.

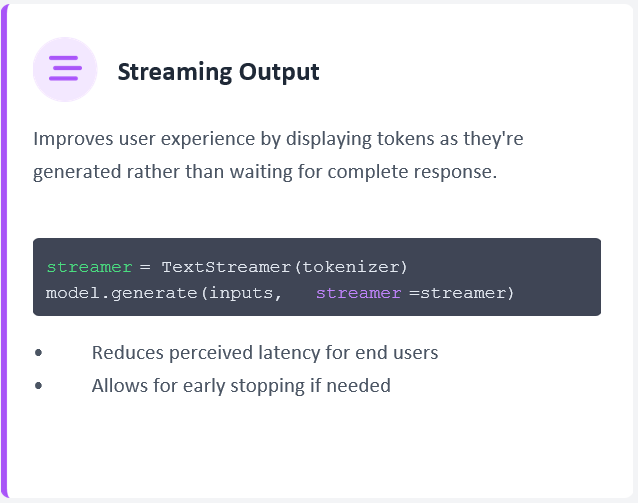
3. Generating Text with Streamer
To generate text efficiently and display it as it streams, we use the TextStreamer:
def generate_text(model_name: str, messages: list, max_new_tokens=80):
model, tokenizer = load_model(model_name)
inputs = tokenizer(messages, return_tensors="pt", padding=True, truncation=True).to("cuda")
streamer = TextStreamer(tokenizer)
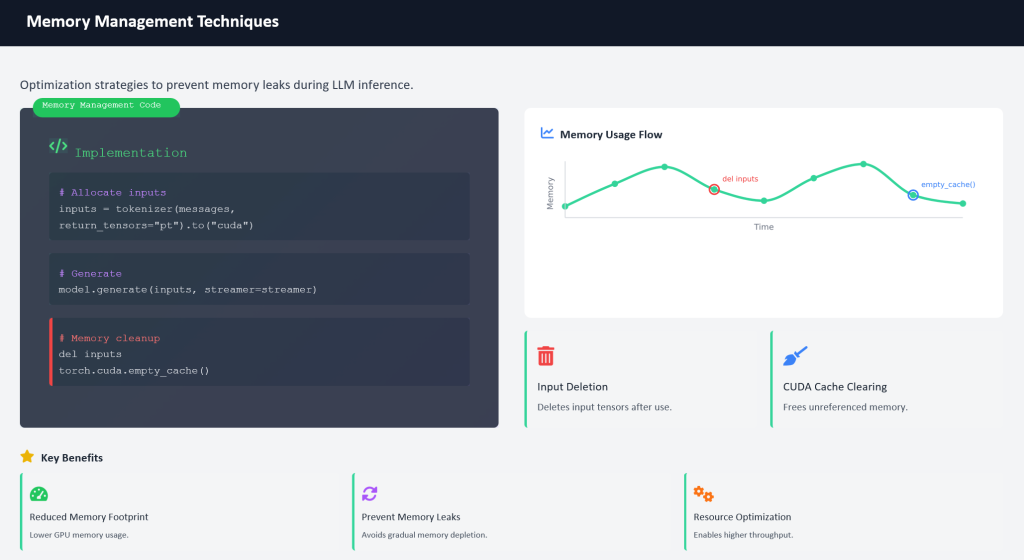
model.generate(inputs, streamer=streamer, max_new_tokens=max_new_tokens)
# 釋放部分顯存
del inputs
torch.cuda.empty_cache()TextStreamerallows us to see the output in real-time.
- Inputs are tokenized and sent to GPU for fast inference.

4. Unified Interface for Multiple Models
We wrapped the logic in a single function, generate_text, which takes a model name and messages:
generate_text("LLAMA", messages)
generate_text("PHI3", messages)
generate_text("GEMMA2", messages)- Supports any model listed in
MODEL_DICT.
- Automatically loads the model if not already in memory.
- Handles GPU memory efficiently by deleting unused inputs after generation.
5. Benefits of This Approach
- Memory efficiency with 4-bit quantization.
- Fast inference using half-precision compute.
- Flexible multi-model management, no need to reload models every time.
- Real-time output streaming for interactive applications.
Conclusion
With just a few lines of code, you can run multiple large language models efficiently on a single GPU. 4-bit quantization with BitsAndBytes enables practical deployment of 8B+ parameter models even on consumer-grade GPUs. This approach can be extended to chatbots, AI assistants, and text generation pipelines.
Hugging Face Models
- meta-llama/Meta-Llama-3.1-8B-Instruct
- microsoft/Phi-3-mini-4k-instruct
- google/gemma-2-2b-it
- Qwen/Qwen2-7B-Instruct
- mistralai/Mixtral-8x7B-Instruct-v0.1
If you’d like to explore more tutorials like this, check out our AI category for related guides.