Seaborn資料分析 + Sklearn
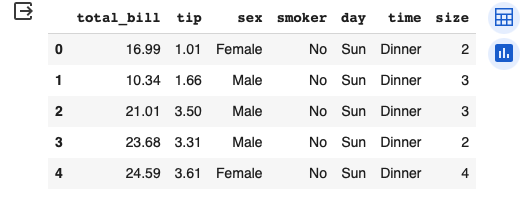
Seaborn 資料集中的 “tips” 是一個包含餐廳小費資料的資料集。這個資料集通常用於示範 Seaborn 中的數據可視化功能和統計分析。
“tips” 資料集包含了餐廳服務員收到的小費金額以及與小費相關的一些額外信息,例如顧客人數、就餐日期和時間、就餐者的性別、是否是吸煙區域、就餐的星期幾等等。這些信息可以用於探索性數據分析、統計分析以及建模工作。
這個資料集的結構通常包含以下幾個欄位:
- total_bill:總消費金額(含小費)。
- tip:小費金額。
- sex:就餐者的性別。
- smoker:是否吸煙。
- day:就餐的星期幾。
- time:就餐的時間(午餐或晚餐)。
- size:就餐者的人數。
這個資料集是 Seaborn 中內建的範例資料集之一,通常用於示範 Seaborn 中各種圖表的繪製和數據分析。
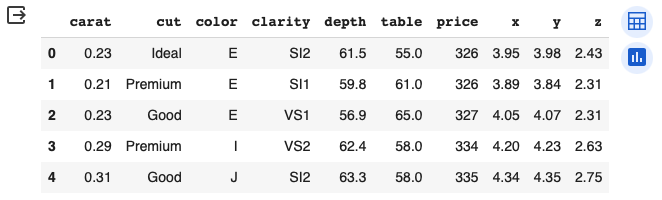
Seaborn 資料集中的 “diamonds” 是一個包含鑽石價格和屬性的資料集。這個資料集通常用於示範 Seaborn 中的數據可視化功能和統計分析。
“diamonds” 資料集包含了各種鑽石的屬性和價格信息。這些屬性包括鑽石的重量(克拉)、切工、顏色、淨度等,而價格則是以美元為單位。
這個資料集的結構通常包含以下幾個欄位:
- carat:鑽石的重量(克拉)。
- cut:鑽石的切工質量,包括 Fair、Good、Very Good、Premium 和 Ideal 等級。
- color:鑽石的顏色,從 J(最差)到 D(最好)。
- clarity:鑽石的淨度,包括 I1、SI2、SI1、VS2、VS1、VVS2、VVS1 和 IF 等級。
- depth:鑽石的深度比例(百分比)。
- table:鑽石的平頂比例(百分比)。
- price:鑽石的價格(美元)。
- x、y、z:鑽石的長寬高尺寸(毫米)。
這個資料集通常用於示範 Seaborn 中的散點圖、直方圖、盒圖等圖表的繪製,以及數據探索和統計分析。
Categorical Feature
在機器學習和統計建模中,Categorical Feature(分類特徵)是指具有有限數量可能值的特徵或變量。這些可能的值是離散的並且不具有順序關係。分類特徵通常描述了特定的類別、類型或類別,而不是數值或連續性數據。
例如,在一個房地產數據集中,”地區”可以是一個分類特徵,因為它可以被劃分為有限的類別,如 “市中心”、”市郊” 和 “郊區”。又或者在一個網站用戶行為數據集中,”瀏覽器類型” 可能是一個分類特徵,因為它可以被劃分為類別,如 “Chrome”、”Firefox” 和 “Safari”。
處理分類特徵的一種常見方法是對其進行One-Hot Encoding(一位有效編碼)。這將把分類特徵轉換為二進制向量,使其適合於機器學習算法的輸入。另一種方法是將分類特徵轉換為整數編碼,即將每個可能的類別映射到一個整數值。這兩種方法都可以將分類特徵轉換為數值表示形式,從而使其適用於機器學習算法。
Ordinal Encoding
Ordinal Encoding(序數編碼)是一種將分類特徵轉換為數值表示形式的技術,其中每個類別都被映射到一個整數值。與 One-Hot Encoding 不同,序數編碼將類別映射到整數值,而不是創建二進制向量。這種方法適用於那些具有順序關係的類別,即類別之間存在某種自然的順序。
例如,假設有一個類別特徵 “教育程度”,其可能的值包括 “高中”、”大學” 和 “碩士”。這些值之間存在一種自然的順序,因為 “碩士” 學位通常高於 “大學” 學位,而 “大學” 學位又高於 “高中” 學歷。在這種情況下,可以將 “高中”、”大學” 和 “碩士” 分別映射到整數值 0、1 和 2。
序數編碼通常用於處理具有順序關係的分類特徵,以便將它們轉換為數值表示形式,使其適合於機器學習算法的輸入。然而,需要注意的是,使用序數編碼時,應該確保所選擇的整數值能夠準確地反映類別之間的相對順序,以避免對模型的影響產生不良影響。
One-Hot Encoding
One-Hot Encoding(一位有效編碼)是一種在機器學習和數據處理中常用的技術,用於將分類變量表示為二進制向量。它將分類變量轉換為一種形式,可以提供給機器學習算法,以改善模型的性能和準確性。
在 One-Hot Encoding 中,每個類別被表示為一個二進制向量,其中除了對應於該類別的一個元素被設置為 1 之外,所有元素都是零。這樣就創建了分類變量的二進制表示,使其適用於期望數值輸入的機器學習算法。
以下是一個例子來說明 One-Hot Encoding:
假設我們有一個分類變量 “顏色”,有三個類別:紅色、綠色和藍色。使用 One-Hot Encoding,我們可以將這些類別表示為二進制向量:
- 紅色:[1, 0, 0]
- 綠色:[0, 1, 0]
- 藍色:[0, 0, 1]
現在,每個類別都被表示為一個二進制向量,其中一個元素設置為 1,對應於該類別。
One-Hot Encoding 在各種機器學習任務中廣泛使用,例如分類和回歸,當處理分類變量時。它有助於防止模型錯誤地假設類別之間的有序關係,並允許模型有效地從分類數據中學習。
Ordinal Encoding vs One-Hot Encoding
當碰到分類特徵時,建議根據數據的特性和機器學習模型的需求來選擇是使用Ordinal Encoding還是One-Hot Encoding進行轉換。
Ordinal Encoding 的優缺點:
優點:
- 保留了類別之間的順序關係,對於有序分類特徵來說更符合直覺。
- 生成的特徵維度較低,節省了數據空間。
- 在某些情況下,可以提供更好的解釋性,因為整數編碼可以直接反映不同類別之間的相對關係。
缺點:
- 可能會引入錯誤的順序假設,對於沒有明確順序的分類特徵可能不適用。
- 數值之間的差異可能被模型誤解為具有固定的大小或間隔,導致模型偏差。
- 如果特徵的數量很大,而其中的類別數量較少,則可能浪費了大量的內存空間。
One-Hot Encoding 的優缺點:
優點:
- 不會引入任何錯誤的順序假設,適用於沒有明確順序的分類特徵。
- 每個類別都是獨立的二進制變量,避免了將類別解釋為具有固定大小或間隔的風險。
- 可以避免在特徵數量較大時導致的內存浪費。
缺點:
- 生成的特徵維度較高,可能會導致所謂的維度災難,增加模型的計算成本和複雜性。
- 無法保留類別之間的順序關係,可能會丟失一些信息,特別是對於具有明確順序的分類特徵來說。
總的來說,當分類特徵具有明確的順序關係時,通常建議使用Ordinal Encoding;而當分類特徵沒有明確的順序關係時,則建議使用One-Hot Encoding。根據機器學習模型的需要以及數據的特性,選擇適合的編碼方法可以幫助提高模型的性能和準確性。
線性回歸(Linear Regression)
LinearRegression 是 scikit-learn 庫中的一個類別,用於 Python 編程語言,用於線性回歸任務。它是一種最簡單的線性模型,用於建模自變量和因變量之間的線性關係。
以下是關於 LinearRegression 的意義及用途的說明:
- 意義:LinearRegression 用於建立自變量(特徵)與因變量之間的線性關係模型。它的基本假設是,因變量與自變量之間存在線性關係,可以用一條直線(在一維情況下)或者一個超平面(在高維情況下)來描述這種關係。
- 用途:
- 預測任務:LinearRegression 主要用於預測任務,其中目標是根據輸入特徵來預測連續型的因變量。例如,根據房屋的各種特徵(如面積、臥室數量、地理位置等),預測房屋的價格。
- 關聯性分析:線性回歸也用於分析自變量與因變量之間的關聯性。通過模型的係數,可以了解每個自變量對因變量的影響程度,以及它們之間的方向關係(正相關或負相關)。
- 參數估計:線性回歸還可以用於估計模型中的參數,如斜率和截距。這些參數對於理解模型的行為和做出預測是非常重要的。
- 模型評估:除了預測和關聯性分析,線性回歸還可以用於評估模型的性能。通過比較預測值與實際觀測值之間的差異,可以評估模型的擬合優度。
總之,LinearRegression 是一個簡單但非常有用的線性模型,適用於許多回歸任務,特別是在數據集具有線性結構且特徵空間不太複雜的情況下。
KNeighborsRegressor
KNeighborsRegressor 是 scikit-learn 庫中的一個類別,用於 Python 編程語言,用於回歸任務。它屬於基於鄰近的學習方法,通常用於建模連續型的因變量和一個或多個自變量之間的關係。
以下是關於 KNeighborsRegressor 的意義及用途的說明:
- 意義:KNeighborsRegressor 使用基於鄰居的方法來進行回歸預測。它的基本思想是:對於一個新的數據點,通過查找與該點最近的 K 個鄰居的目標值(因變量值),然後利用這些鄰居的目標值來進行預測。具體來說,預測值通常是這些鄰居目標值的平均值或加權平均值。
- 用途:
- 預測任務:KNeighborsRegressor 通常用於預測任務,其中目標是根據輸入特徵來預測連續型的因變量。例如,根據房屋的各種特徵(如面積、臥室數量、地理位置等),預測房屋的價格。
- 探索性數據分析:通過查看數據點的近鄰,可以幫助了解數據的分佈和結構。這對於探索性數據分析非常有用,可以幫助發現數據中的模式和趨勢。
- 回歸模型的基準測試:KNeighborsRegressor 可以用作其他回歸模型的基準測試,以幫助評估更複雜模型的性能。尤其是對於數據較少或者特徵空間較小的情況下,它可以作為一個簡單但有效的基準模型。
- 注意事項:
- 參數選擇:在使用 KNeighborsRegressor 時,需要選擇適當的參數,特別是鄰居數量 n_neighbors。選擇合適的鄰居數量對於模型的性能至關重要。
- 數據預處理:與大多數機器學習算法一樣,數據預處理也很重要。在使用 KNeighborsRegressor 之前,需要對數據進行特徵縮放和處理缺失值等預處理步驟。
總之,KNeighborsRegressor 是一個簡單而有效的回歸模型,適用於許多回歸任務,特別是在數據集較小、特徵空間較小或需要進行探索性數據分析時。
RandomForestRegressor
RandomForestRegressor 是 scikit-learn 中的一個類別,用於 Python 程式語言,用於回歸任務。它屬於集成學習中的一種方法,基於隨機森林算法。
以下是關於 RandomForestRegressor 的意義及用途的說明:
- 意義:RandomForestRegressor 用於建立多個決策樹的集成模型,通過結合這些決策樹的預測結果來進行回歸預測。每個決策樹都是基於隨機樣本和隨機特徵進行構建,因此具有一定的隨機性,這有助於減少過擬合和提高模型的泛化能力。
- 用途:
- 預測任務:RandomForestRegressor 主要用於預測連續型的因變量。它可以應用於各種領域,如金融、醫療、零售等,用於預測股票價格、疾病發生率、銷售量等連續型數據。
- 特徵重要性分析:隨機森林可以計算每個特徵的重要性,這有助於了解哪些特徵對於模型的預測能力最為重要。這對於特徵選擇和模型解釋非常有用。
- 處理大型數據集:由於隨機森林的並行性和可擴展性,它們通常能夠有效處理大型數據集,包括高維數據和大量樣本。
- 抗過擬合能力:由於隨機森林的隨機性特性,它們通常對於過擬合具有較強的抗性。因此,即使在較少的數據量下,隨機森林也能夠產生良好的預測結果。
總之,RandomForestRegressor 是一種強大且靈活的機器學習模型,適用於各種回歸任務,並且通常能夠產生準確且穩健的預測結果。
SVM
支持向量機(Support Vector Machine,SVM)是一種用於監督式學習的機器學習模型。它的主要目標是找到一個最佳的超平面來區分不同類別的數據點。以下是關於 SVM 的意義及用途的說明:
- 意義:SVM 的核心概念是將數據映射到高維空間,從而使得數據在這個空間中可以被一個超平面有效地分割。這個超平面可以最大化類別之間的邊際(margin),從而提高模型的泛化能力。
- 用途:
- 分類任務:SVM 主要用於二元分類任務,即將數據分成兩個類別。通過找到一個最佳的超平面,SVM 可以有效地區分不同類別的數據點。此外,SVM 也可以通過使用多個二元 SVM 構建多類別分類器。
- 回歸任務:除了分類,SVM 還可以用於回歸任務。支持向量回歸(Support Vector Regression,SVR)通過找到一個最佳的超平面來進行連續型目標變量的預測。
- 特徵空間映射:SVM 可以使用不同的核函數來將數據映射到高維空間,從而實現非線性分類。這使得 SVM 在處理非線性問題時非常有效。
- 異常檢測:由於 SVM 能夠找到最佳的分割超平面,因此它也常被用於異常檢測任務中,即識別數據中的異常或極端值。
- 文本分類:SVM 在文本分類任務中也經常被使用,例如垃圾郵件檢測、情感分析等。
總之,SVM 是一個多功能的機器學習模型,廣泛應用於分類、回歸、特徵空間映射、異常檢測等各種任務中。它以其優秀的泛化能力和有效的非線性分類能力而聞名。